
In Part 1, we addressed the uncomfortable reality that patching is not always possible.
In Part 2, we showed that compensatory controls only matter if their effectiveness can be measured.
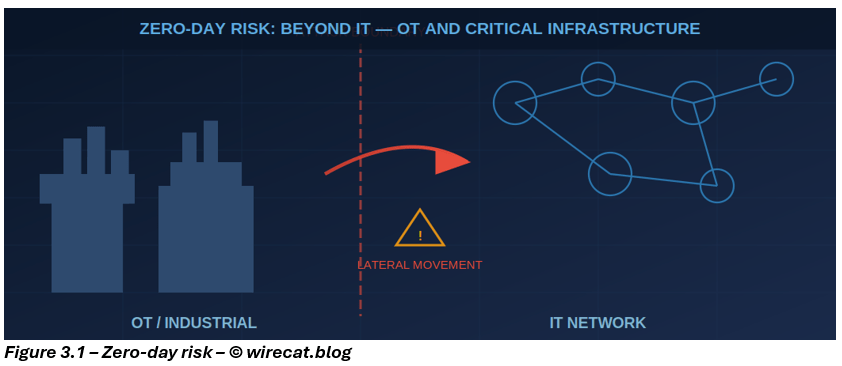
Now comes the part many organizations overlook: The same risk logic does not stop at IT. In fact, it becomes even more critical in OT and operational environments.
This is where the stakes change. A zero-day in a legacy IT application may disrupt a business process.
A zero-day in an OT or industrial environment can affect:
- physical operations,
- safety systems,
- environmental controls,
- production output,
- and in some cases, human life.
And unlike IT, where patching can sometimes be scheduled over a weekend, OT systems often operate under constraints that make patching the exception, not the norm.
This is why the principles from Parts 1 and 2 are not just useful in OT. They are essential.
1. Why patching is even harder in OT than in IT
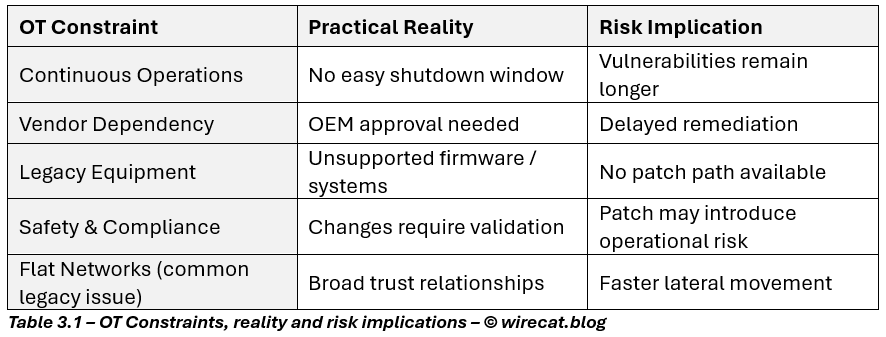
If Part 1 was about business constraints, OT introduces operational reality. In industrial environments:
- Systems may run 24/7 with no maintenance windows
- OEM support is tightly controlled
- Patch validation may require factory testing or safety recertification
- Legacy PLCs, HMIs, and control servers may have limited security support
- Downtime can disrupt physical production or supply chains
The question in OT is rarely: “Can we patch?” It is more often: “Can we patch without stopping operations or creating safety risk?”
That changes everything. Why patching is difficult in OT environments?
This is why OT security must be built around risk reduction, containment, and resilience, not patching alone.
2. The attack path in OT is different — but the risk logic is the same
Threat actors targeting OT are no longer theoretical. Recent years have shown:
- ransomware disrupting industrial sites,
- malware targeting control systems,
- adversaries abusing remote access pathways,
- and attackers moving from IT into OT through poorly segmented networks.
But despite the differences in technology, the risk logic remains familiar: If vulnerability cannot be removed, reduce exploitability, reduce exposure, and limit operational impact.
That is the same principle from Part 1, only now the consequences are higher.
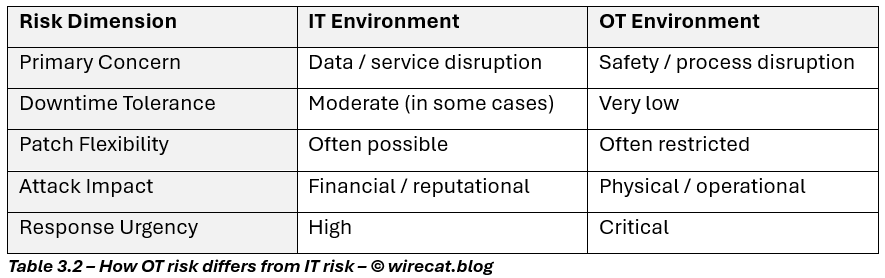
The logic is the same. The tolerance for failure is not.
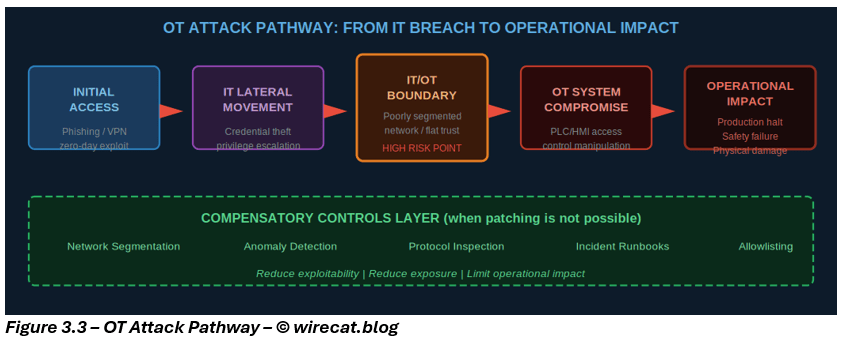
3. What compensatory controls look like in OT
This is where many organizations make mistakes. They assume OT requires completely different security thinking. It doesn’t. What OT requires is the same principles, adapted to industrial reality.
The goal remains:
- reduce attack paths,
- detect abnormal behaviour early,
- contain impact quickly.
The controls may look different in implementation, but their risk purpose is identical.
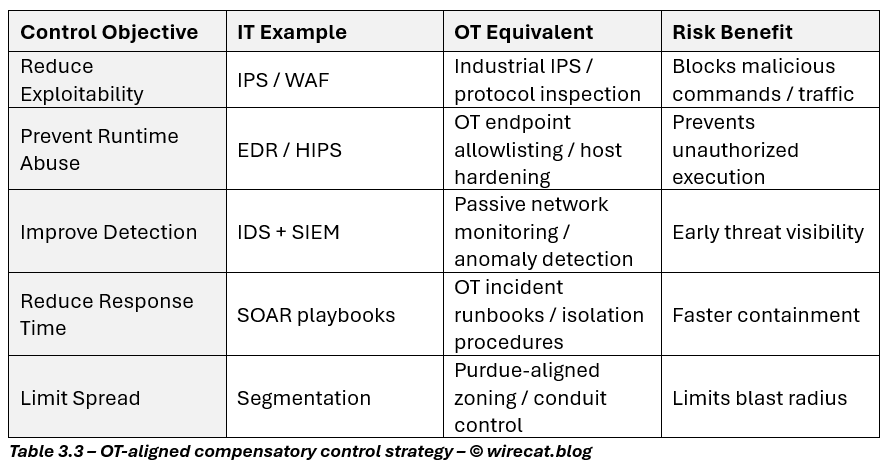
The point is not to replicate IT tools blindly. The point is to ensure: every missing primary control has a deliberate compensatory treatment.
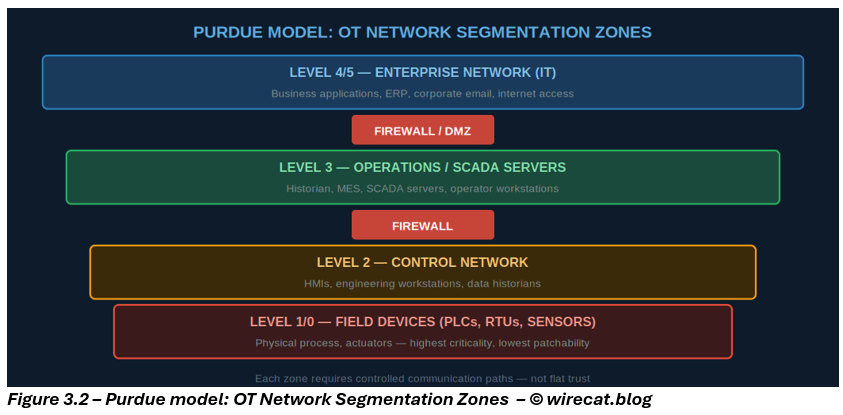
4. The most important OT control: segmentation and trust boundaries
If there is one control that consistently changes the risk equation in OT, it is segmentation.
Why? Because in OT, trust relationships are often inherited:
- engineering workstations can talk to controllers,
- HMIs trust servers,
- vendors have remote pathways,
- flat networks allow broad access.
In this environment, one compromise can quickly become an operational event. Segmentation changes that.
Good OT segmentation:
- separates IT from OT securely
- isolates critical assets by process / function
- restricts east-west traffic
- enforces least communication pathways
- limits remote access
This is not just architecture. It is operational risk containment.
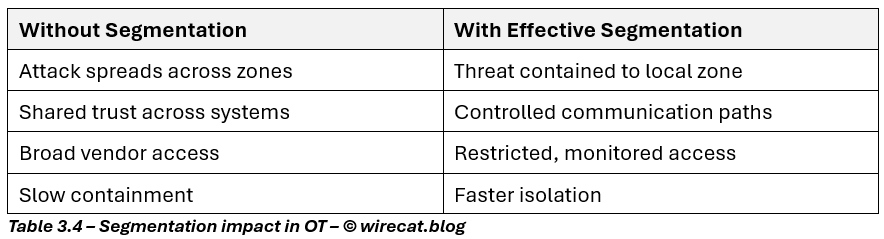
In OT, segmentation often does more for resilience than patching alone ever could.
5. Proving resilience: OT needs evidence too
Just like in Part 2, OT compensatory controls must be validated. In fact, this matters even more in industrial environments because assumptions can be dangerous.
Organizations should ask:
- Are OT assets visible and inventoried?
- Are network flows understood?
- Are vendor remote sessions controlled?
- Are anomaly alerts actionable?
- Can OT incidents be isolated without stopping the plant?
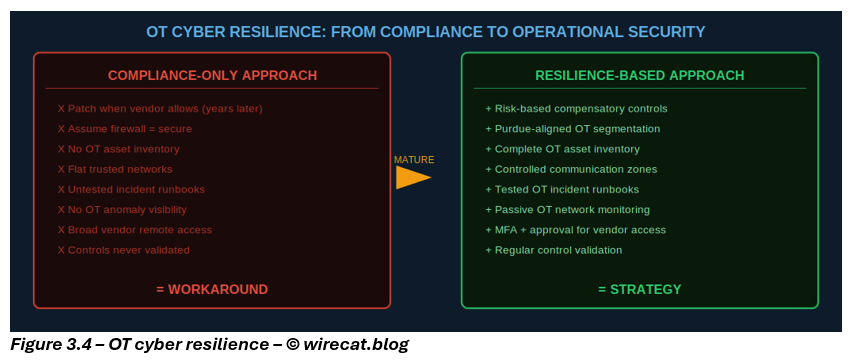
Because in OT: A control that has never been tested is not a control. It is an assumption.

This is what turns OT security from compliance into resilience.
6. The bigger lesson: cyber resilience is not built on patching alone
Across all three parts, one principle remains constant: Security is not about whether a vulnerability exists. It is about whether that vulnerability can be exploited in a way that materially harms the business.
That is the real test.
- When patching is possible, patch.
- When patching is delayed, reduce exposure.
- When patching is impossible, compensate intelligently.
- And in all cases, measure whether your controls are working.
That is how mature organizations operate. Not by pretending risk can be eliminated. But by making it visible, reducing it deliberately, and governing it honestly.
Final closing
Legacy systems, vendor-locked applications, and industrial environments are not signs of poor security. They are operational realities.
What matters is not whether your environment is perfect.
What matters is whether:
- you understand your exposure,
- you have layered compensatory controls,
- you validate them regularly,
- and you can defend your residual risk with confidence.
That is what separates a workaround from a strategy. And that is what real cyber resilience looks like.

Leave a comment